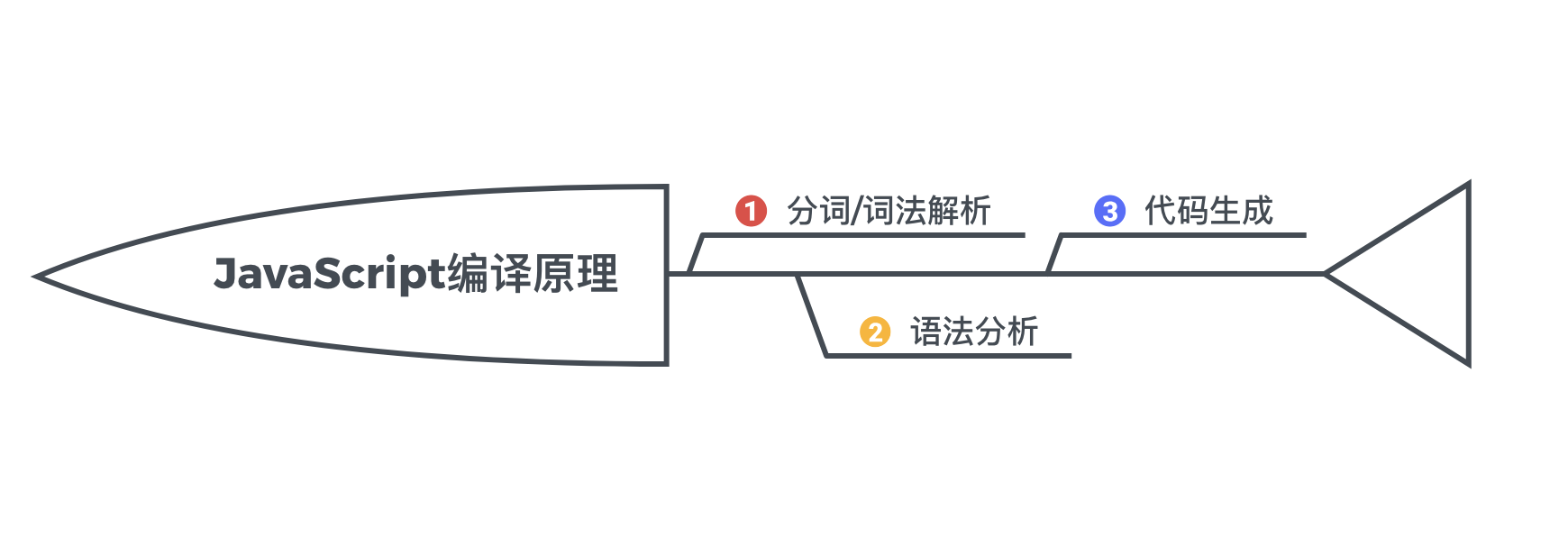
封装 fetch 请求
- 如果只是简单的请求,没必要引入
aixos,通过将fetch请求的相关代码封装在request.js/request.ts文件中,在使用的时候引入相关请求方法即可,好处有几点:- 请求的地方代码更少。
- 公共的错误统一在一个地方添加即可。
- 请求定制的错误还是请求自己也可以处理。
- 扩展性好,添加功能只需要改一个地方。
- 下面给出我在项目中封装的 request.ts 文件具体内容:
1 | // path:src/utils/request.ts |
- 根据功能建立不同的请求模块,如列表模块:
1 | // path:src/services/api/list.ts |
- 暴露 api:
1 | // path:src/services/api.ts |
- 组件中使用:
1 | // path:src/components/xxx.tsx |
- 以上则成功完成
fetch请求的封装。
 简单来说就是你想访问目标服务器的权限,但是没有权限。这时候代理服务器有权限访问服务器,并且你有访问代理服务器的权限,这时候你就可以通过访问代理服务器,代理服务器访问真实服务器,把内容给你呈现出来。
简单来说就是你想访问目标服务器的权限,但是没有权限。这时候代理服务器有权限访问服务器,并且你有访问代理服务器的权限,这时候你就可以通过访问代理服务器,代理服务器访问真实服务器,把内容给你呈现出来。